
Why AI-Generated Chinese Names Often Fail Validation
You ask an AI to generate a Chinese name and it spits out something that looks convincing. The characters render correctly, the structure appears right, and the pinyin seems plausible. But show that name to a native speaker and you'll get a raised eyebrow or an outright laugh. The name might be structurally impossible, culturally offensive, or simply nonsensical in ways that only someone fluent in Chinese naming conventions would catch.
This is a growing problem across multiple industries. Fiction writers need authentic character names for stories set in China. Game developers building open-world RPGs need thousands of NPC names that feel real. Business localization teams need culturally appropriate names for marketing personas and user testing. And compliance professionals generating synthetic test data for KYC/AML screening systems need names that mirror actual naming patterns without using real identities.
The stakes vary, but the core challenge is the same: AI models treat Chinese name generation as a pattern-matching exercise without understanding the linguistic, tonal, and cultural rules that govern real names. This article provides a systematic, step-by-step methodology for catching those errors, whether you're validating a single random chinese name or auditing thousands of AI outputs at scale.
Why AI Models Struggle With Chinese Name Generation
When you use a chinese name generator or prompt a large language model to generate chinese name options, the outputs often contain hallucination patterns that are invisible to non-speakers. Research into language and cultural bias in AI has shown that models trained predominantly on English-language data perform significantly worse on tasks requiring deep cultural knowledge of Chinese language systems. This bias extends directly to name generation.
The most common failures include invalid character combinations where two characters that individually exist in Chinese are paired in ways no native speaker would ever combine. AI models also produce nonsensical surname-given name pairings, placing characters that function only as given name elements into the surname position. Some outputs include characters that exist in Unicode but are archaic, region-specific, or simply never used in personal names. Tonal clashes round out the problem, where every character in a generated name shares the same tone, producing something that sounds flat and artificial when spoken aloud.
These issues stem from how ai chinese language models learn. They absorb statistical patterns from text corpora without internalizing the cultural logic behind naming. A model might see a character appear frequently in text and assume it works in a name, even if that character is reserved for place names, literary references, or technical vocabulary.
Who Needs to Validate AI-Generated Chinese Names
The audience for validation spans creative and technical fields alike. Writers exploring tools like a chinese name generator perchance encounter need confidence that their character names won't break immersion for Chinese-speaking readers. Game studios localizing titles for the Chinese market risk player backlash if NPC names feel robotic or culturally tone-deaf. Localization teams adapting brand materials need names that carry the right connotations. And compliance teams at financial institutions face real regulatory risk if their synthetic test data doesn't reflect authentic Chinese naming conventions, since unrealistic names can skew screening system calibration.
Regardless of your use case, here are the five most common AI generation failures this guide will teach you to catch:
- Surnames that don't exist in any recorded Chinese surname database
- Characters outside the standard range used in modern Chinese personal names
- Gender-mismatched given name characters that immediately signal inauthenticity
- Tonal patterns that sound unnatural or monotonous when spoken aloud
- Homophone conflicts that create embarrassing or inauspicious meanings
Each of these failure modes maps to a specific validation step. The first and most fundamental check starts with the surname itself, the single character that anchors every Chinese name and carries centuries of genealogical weight.

Step 1: Verify the Surname Against Known Chinese Surname Records
A Chinese name lives or dies by its surname. Unlike given names, which allow for creative expression, surnames draw from a finite, well-documented pool. If an AI generates a surname that doesn't exist in that pool, the entire name collapses on contact with any native speaker. The good news? Surname verification is the fastest and most objective check you can perform.
China has roughly 6,000 surnames currently in use, distilled from over 24,000 historically recorded across all ethnic groups. But here's the critical insight: the top 100 surnames account for approximately 85% of the entire national population. That concentration makes validation straightforward. If a chinese surname generator or AI model produces a surname outside the common corpus, it deserves immediate scrutiny.
Cross-Referencing the Hundred Family Surnames Database
The foundational reference is the Hundred Family Surnames (百家姓, Bai Jia Xing), a Song Dynasty text dating back over 1,000 years. While the original listed several hundred surnames, modern census data from China's Ministry of Public Security provides precise frequency rankings you can check against.
When you need to find chinese name validity, start with the 2020 National Census data. The top five surnames alone, Wang, Li, Zhang, Liu, and Chen, cover 30.8% of the registered population. The top ten push that figure past 42%. Any AI-generated name using one of these common surnames passes the first plausibility gate immediately.
For less common surnames, cross-reference against published lists of the top 400 surnames, which cover populations exceeding 80,000 individuals each. Resources like HanNames provide searchable databases ranked by frequency. If the generated surname doesn't appear in any authoritative list, treat it as a red flag requiring further investigation.
Spotting Fabricated or Misused Surname Characters
AI models hallucinate surnames in predictable ways. Knowing the patterns helps you catch errors quickly, even if you're working with a chinese name from english inputs or unfamiliar characters.
Watch for these red flags:
- Valid characters that never function as surnames. A character like 的 (de, a grammatical particle) or 很 (hen, meaning "very") exists in Chinese but would never appear as a surname. AI models sometimes select characters based on frequency in general text rather than frequency in names.
- Extremely rare surnames presented as common. A surname like 死 (si, meaning "death") technically exists in historical records but is vanishingly rare. If an AI produces it without specific prompting for unusual names, the model is likely hallucinating from its training data.
- Mangled compound surnames (复姓). Compound surnames like 欧阳 (Ouyang), 司马 (Sima), or 诸葛 (Zhuge) consist of two characters that must appear together. AI models frequently split them, using only one character, or worse, combine two single-character surnames into a fake compound. The most common compound surname, 欧阳, has a population of roughly 1.1 million, while others like 司马 have only about 23,000 bearers. If an AI generates a two-character surname that isn't on the recognized compound surname list, it's almost certainly fabricated.
The table below gives you a quick-reference benchmark. If an AI-generated surname matches one of these top 20, you can move confidently to the next validation step.
| Rank | Surname | Pinyin | Approx. Population (millions) | Percentage of Total |
|---|---|---|---|---|
| 1 | 王 | Wang | 101.8 | 7.21% |
| 2 | 李 | Li | 101.4 | 7.18% |
| 3 | 张 | Zhang | 95.8 | 6.78% |
| 4 | 刘 | Liu | 72.3 | 5.12% |
| 5 | 陈 | Chen | 63.7 | 4.51% |
| 6 | 杨 | Yang | 46.3 | 3.28% |
| 7 | 黄 | Huang | 33.9 | 2.40% |
| 8 | 赵 | Zhao | 28.7 | 2.03% |
| 9 | 吴 | Wu | 28.0 | 1.98% |
| 10 | 周 | Zhou | 26.9 | 1.91% |
| 11 | 徐 | Xu | — | ~1.73% |
| 12 | 孙 | Sun | — | ~1.62% |
| 13 | 马 | Ma | — | ~1.52% |
| 14 | 朱 | Zhu | — | ~1.30% |
| 15 | 胡 | Hu | — | ~1.20% |
| 16 | 郭 | Guo | — | ~1.10% |
| 17 | 何 | He | — | ~1.05% |
| 18 | 林 | Lin | — | ~1.01% |
| 19 | 高 | Gao | — | ~0.98% |
| 20 | 罗 | Luo | — | ~0.95% |
A surname passing this check confirms only one piece of the puzzle. The characters that follow it, the given name, introduce an entirely different set of validation challenges, starting with whether those characters even belong in a personal name at all.
Step 2: Check Character Validity Using CJK Unicode Ranges
A surname might check out perfectly, but the given name characters can still betray an AI's lack of understanding. Some models pull from obscure Unicode blocks, producing characters that technically render on screen yet would never appear on a Chinese ID card or birth certificate. Catching these requires a character-level validity check rooted in how Unicode organizes CJK ideographs.
Every ai chinese character used in a personal name should fall within a specific, well-defined range. When a chinese name generator with characters outputs something outside that range, you're looking at either an archaic glyph, a Japanese-only kanji, or a character so rare it signals machine fabrication instantly.
Using CJK Unicode Ranges for Character Validation
The primary valid range for modern Chinese name characters is the CJK Unified Ideographs block, spanning U+4E00 to U+9FFF. This block contains 20,992 code points covering the most common ideographs used in modern Chinese, Japanese, Korean, and Vietnamese writing. For Chinese personal names specifically, the vast majority of valid characters live here.
But not every character in this block belongs in a name. Here's how the broader CJK landscape breaks down:
- CJK Unified Ideographs (U+4E00 to U+9FFF): The core block. Most legitimate Chinese name characters reside here. This is your primary validation target.
- CJK Extension A (U+3400 to U+4DBF): Contains rarer characters. A small number appear in names, particularly regional or ethnic minority names, but most are uncommon enough to warrant a flag.
- CJK Extensions B through I (U+20000 and beyond): Archaic, historical, or highly specialized characters. These almost never appear in modern personal names. If an AI outputs characters from these ranges, treat it as a strong indicator of hallucination.
- CJK Compatibility Ideographs (U+F900 to U+FAFF): Duplicate encodings for legacy compatibility. Characters here are typically Korean or Japanese variants and should not appear in Chinese names.
A practical rule of thumb: if every character in the generated name falls within U+4E00 to U+9FFF, it passes the basic range check. Characters from Extension A deserve a second look. Anything beyond that is almost certainly wrong for a chinese character name generator output intended to represent a modern Chinese person.
Programmatic Character Checks for Developers
If you're validating names at scale, whether for game NPC databases, synthetic test data, or localization pipelines, you'll want to automate this. A simple validation script can catch range violations in milliseconds. The approach uses Python's Unicode handling to inspect each character's code point directly.
Here's the sequential process for building a character validity checker:
- Extract each character from the generated name string individually, separating the surname position from given name positions.
- Check the Unicode code point of each character using
ord(char)in Python. Verify it falls within U+4E00 to U+9FFF for the primary range. - Flag characters outside the standard range. If a character lands in Extension A (U+3400 to U+4DBF), mark it for manual review. If it falls in Extensions B+ or Compatibility blocks, reject it outright.
- Verify stroke count reasonableness. Most Chinese name characters have between 3 and 25 strokes. Characters with extremely high stroke counts (30+) are typically archaic or compound forms unsuitable for names. Cross-reference against a stroke count dictionary.
- Check for non-CJK intrusions. Confirm no Latin characters, punctuation, numbers, or characters from Hiragana/Katakana ranges (U+3040 to U+30FF) have slipped into the output.
- Validate character frequency. Cross-reference each character against a name-frequency corpus. Characters that appear in general Chinese text but have zero or near-zero occurrences in name databases are likely invalid for naming purposes.
For teams looking for a ready-made reference implementation, the GitHub sinonym project demonstrates normalization approaches for Chinese name formatting, including handling of variant characters and simplified-traditional conversion. It provides a useful starting point for building your own validation pipeline rather than coding everything from scratch.
Character validity confirms that the raw building blocks are legitimate. But valid characters can still combine in ways that feel deeply wrong to native speakers, particularly when gender signals clash with the name's intended use.

Step 3: Validate Gender Appropriateness of Given Name Characters
Imagine naming a burly male warrior character 婷婷 (Tingting) or giving a delicate female protagonist the name 刚强 (Gangqiang). To a native Chinese speaker, these names land like calling a lumberjack "Daisy" or a ballerina "Butch," except the dissonance runs even deeper because Chinese characters carry gender meaning in their very structure, their radicals, and their semantic roots.
Chinese given name characters encode gender through layers of cultural association that AI models routinely miss. A dataset of over 30 million Chinese individuals published in Scientific Data found that more than 80% of people carry names with a gender ratio above 0.9, meaning the characters in their given names are used overwhelmingly by one gender. When an AI scrambles these signals, the result reads as immediately artificial to anyone familiar with Chinese naming conventions.
Identifying Strongly Gendered Name Characters
Chinese name characters cluster into recognizable gender categories based on their semantic fields. Research into gendered naming practices in Mandarin Chinese confirms that these associations draw on metaphoric imagery tied to cultural ideals of femininity and masculinity. The patterns are consistent enough that gender prediction from Chinese characters alone achieves precision rates of 79% to 94% depending on the threshold applied.
Feminine characters typically draw from these semantic domains:
- Beauty and appearance: 婷 (graceful), 娜 (elegant), 丽 (beautiful), 媛 (beauty)
- Flowers and plants: 芳 (fragrant), 莲 (lotus), 梅 (plum blossom), 兰 (orchid)
- Jade and precious things: 玉 (jade), 珍 (precious), 琳 (fine jade), 瑶 (jasper)
- Grace and virtue: 雅 (refined), 淑 (gentle), 慧 (wise), 静 (quiet)
Masculine characters pull from a different set of associations entirely:
- Strength and power: 强 (strong), 刚 (firm), 勇 (brave), 威 (mighty)
- Ambition and achievement: 志 (ambition), 伟 (great), 杰 (outstanding), 鹏 (mythical roc)
- Nature and vastness: 海 (sea), 山 (mountain), 峰 (peak), 磊 (rocky/open)
- Moral character: 忠 (loyal), 义 (righteous), 信 (trustworthy), 毅 (resolute)
You'll notice the pattern: feminine characters often contain the 女 (woman) radical or the 艹 (grass/plant) radical, while masculine characters lean toward the 力 (strength) radical or reference large-scale natural features. A chinese name generator female tool that outputs 刚 or 磊 for a woman's name has failed this check completely. Similarly, a chinese male name generator producing 婷 or 淑 for a male character signals a fundamental misunderstanding of how these characters function in names.
The misclassification error rate of standard gender detection tools on Chinese names in Pinyin format ranges from 43% to 94%, largely because romanization strips away the visual and semantic cues embedded in characters. This same information loss affects AI generation: models working from English prompts or Pinyin inputs lack the character-level gender signals that native speakers read instantly.
Handling Gender-Neutral Characters and Modern Naming Trends
Not every character falls neatly into a gendered category. Research on Taiwan's full population naming data shows that about 4.82% of Chinese character names fall into a genuinely gender-neutral zone, where between 40% and 60% of bearers are female. Modern naming trends are pushing more characters toward the center, particularly among younger generations born after 1990.
Characters like 宇 (universe), 晨 (morning), and 睿 (wise) appear frequently in both male and female names without raising eyebrows. The key distinction for validation is separating these legitimately neutral characters from clear violations. A name like 王睿 (Wang Rui) works for either gender. A name like 王婷刚 (Wang Tinggang) jams a strongly feminine character next to a strongly masculine one in the same given name, something no parent would do intentionally.
Here's how to distinguish acceptable ambiguity from obvious errors:
- Clear violation: A strongly gendered character (90%+ single-gender usage) assigned to the opposite gender
- Borderline case: A moderately gendered character (70-90% single-gender usage) used for the less common gender
- Acceptable: A genuinely neutral character (40-60% usage split) used for either gender
The reference table below provides a quick lookup for common characters across all three categories. Use it to spot-check any female chinese name generator or male-targeted output against established usage patterns.
| Category | Character | Pinyin | Meaning | Gender Skew |
|---|---|---|---|---|
| Feminine | 婷 | Ting | Graceful | ~95% female |
| Feminine | 芳 | Fang | Fragrant | ~93% female |
| Feminine | 玉 | Yu | Jade | ~85% female |
| Feminine | 雅 | Ya | Elegant | ~88% female |
| Feminine | 静 | Jing | Quiet, serene | ~90% female |
| Masculine | 强 | Qiang | Strong | ~96% male |
| Masculine | 伟 | Wei | Great | ~95% male |
| Masculine | 刚 | Gang | Firm, hard | ~97% male |
| Masculine | 志 | Zhi | Ambition | ~92% male |
| Masculine | 磊 | Lei | Open, upright | ~98% male |
| Neutral | 宇 | Yu | Universe | ~55% male |
| Neutral | 晨 | Chen | Morning | ~52% male |
| Neutral | 睿 | Rui | Wise, astute | ~50% male |
| Neutral | 涵 | Han | Contain, inclusive | ~48% male |
| Neutral | 思 | Si | Think, ponder | ~45% male |
When validating at scale, you can cross-reference generated characters against the Chinese Gender dataset on Harvard Dataverse, which provides male/female usage ratios for over one million unique given names. Set a threshold, say 0.8, and flag any name where the gender ratio contradicts the intended gender of the generated name. This approach catches the most egregious mismatches while allowing room for the natural ambiguity that exists in real Chinese naming.
Gender alignment confirms that a name's characters match their intended context. But even a gender-appropriate name can sound wrong when spoken aloud if its tonal pattern falls flat, a subtlety that lives entirely in the auditory dimension of Chinese.
Step 4: Assess Tonal Harmony Between Name Characters
Say a generated name out loud. Does it flow, or does it feel like you're stuck on a single note? Mandarin is a tonal language, and Chinese names are designed to be spoken. A name that looks fine on paper can sound monotonous, awkward, or even comical when pronounced, and native speakers pick up on this instantly. Tonal harmony is the dimension that separates names that feel alive from names that feel manufactured.
Understanding the Four Tones in Name Aesthetics
Mandarin has four primary tones plus a neutral tone. First tone (high and level), second tone (rising), third tone (falling-rising), and fourth tone (sharp falling) each give a syllable a distinct melodic shape. The same syllable "ma" means mother, hemp, horse, or scold depending on which tone you apply. In names, these tones interact across two or three characters to create a rhythmic pattern.
The core principle is simple: a well-crafted name avoids awkward tonal collisions. When all characters in a name share the same tone, the result sounds flat and unnatural, like a melody played on one key. Consider a three-character name where the surname is third tone and both given name characters are also third tone. Spoken aloud, it creates a stumbling, repetitive cadence that no parent would choose intentionally.
Good names alternate tones for a pleasing rhythm. The name Li Jinze (李金泽), for example, moves through third tone (Lǐ), first tone (Jīn), and second tone (Zé), creating a dynamic, melodic flow that carries clearly when spoken across a room. This tonal variation is what makes Chinese names sound poetic rather than mechanical. When you use a mandarin name generator or any name generator chinese tool, the output should demonstrate this kind of tonal movement.
Tonal variety is the auditory fingerprint of an authentic Chinese name. A name where every character shares the same tone almost never occurs in real naming practice and should be treated as a strong signal of AI fabrication.
Checking Tone Patterns Against Common Name Conventions
To evaluate tonal flow, look up the pinyin and tone mark for each character in the generated name. Any standard Chinese dictionary or a mandarin name converter tool will provide this. Then assess the sequence:
- All same tone: Almost certainly artificial. Flag immediately.
- Two adjacent same tones: Acceptable in some cases, especially if the third character breaks the pattern. Common in real names but worth a second look.
- All different tones: Ideal. This pattern appears frequently in well-chosen names and signals intentional craftsmanship.
- Third-tone clusters: Particularly problematic. Consecutive third tones trigger a phonological rule called tone sandhi, where the first third tone shifts to a second tone in speech. While native speakers handle this automatically, AI models rarely account for how sandhi changes the perceived sound of a name.
Beyond individual tonal flow, authentic Chinese names often follow generational naming conventions called 字辈 (zibei). In this tradition, one character in the given name is shared across all siblings and cousins of the same generation within a family, while the other character is unique to the individual. These generation characters are predetermined, sometimes documented in family genealogy books spanning dozens of generations.
AI models almost universally ignore zibei patterns. When you create chinese name outputs using AI, the model has no awareness of family lineage constraints. It generates each name in isolation, producing siblings or family members whose names share no generational thread. For fiction writers building family trees or developers populating game worlds with related NPCs, this absence is a dead giveaway. Real Chinese families within the same generation share a character, and that shared character was chosen partly for how its tone interacts with the family surname.
If your use case involves generating multiple names within a family context, verify that the AI has maintained a consistent generation character and that the tonal pattern still works when that shared character is paired with different individual characters. This is where many attempts to create chinese name sets for fictional families fall apart: the generation character clashes tonally with half the individual characters the AI selects.
Tonal harmony confirms that a name sounds right. But sounding right and meaning right are two different things entirely. A name can flow beautifully off the tongue while simultaneously evoking something embarrassing, inauspicious, or culturally taboo through its homophones, a trap that requires its own dedicated layer of scrutiny.
Step 5: Identify Cultural Taboos and Homophone Conflicts
A name can pass every structural check, use a valid surname, contain proper CJK characters, match gender expectations, and flow with tonal variety, yet still be completely unusable. Why? Because when spoken aloud, it sounds like something embarrassing, unlucky, or offensive. This is the cultural layer of validation, and it's the one AI models fail most consistently.
Chinese is a language dense with homophones. A single syllable like "shi" maps to dozens of characters across four tones: 是 (yes), 十 (ten), 死 (death), 事 (matter), 市 (city), and many more. When characters combine in a name, their spoken sounds create secondary meanings that native speakers hear instantly. An AI generating names from character-level statistics has no mechanism for catching these collisions.
Detecting Homophone Conflicts and Unfortunate Meanings
The danger with homophones is that a name might look elegant in written form while sounding terrible in conversation. Consider a name where the given name characters, read together, sound like 死亡 (siwang, death) or 苦难 (kunan, suffering). No amount of beautiful calligraphy saves a name that makes people wince when they hear it. As Chineasy's research on Chinese homophones illustrates, even single-tone differences between characters like 死 (si, die) and 四 (si, four) create confusion in everyday speech. In names, these collisions carry real social consequences.
To check for homophone conflicts, follow this process:
- Read the full name aloud in Mandarin and listen for unintended words or phrases that emerge from the combined syllables
- Check each syllable across all four tones, not just the intended tone, since listeners may mishear or regional accents may shift pronunciation
- Test the name in common sentence patterns like "叫" (jiao, to be called) and "是" (shi, is) to hear how it sounds in natural introduction contexts
- Look for unfortunate meanings when the given name characters are read as a compound word, since two-character given names often form recognizable phrases
- Consider dialect pronunciations if the name will be used in regions where Cantonese, Hokkien, or other varieties are spoken, as homophone conflicts differ across dialects
Anyone using a chinese name maker with meaning should verify that the intended meaning isn't undermined by an accidental homophone. A name designed to evoke "wisdom and prosperity" loses its charm if it sounds like a word for illness when spoken quickly in casual conversation.
Recognizing Cultural Taboos in Character Selection
Beyond homophones, Chinese naming culture carries a set of taboos rooted in centuries of tradition. These aren't arbitrary preferences. They're deeply held beliefs about language, fate, and respect that families take seriously when naming children. AI models trained on general text corpora absorb none of this cultural logic.
The naming taboo system known as 避讳 (bihui) historically prohibited using characters from an emperor's name, and the principle extends into family contexts today. Using the same characters as a direct ancestor, particularly grandparents or great-grandparents, is considered disrespectful in most Chinese families. An ancient chinese name generator or chinese fantasy name generator building character lineages needs to account for this: children in a fictional family cannot share name characters with their elders.
Here are the most common categories of cultural naming taboos to check any AI-generated name against:
- Death and misfortune characters: Characters directly associated with death (死), illness (病), suffering (苦), or decline (衰) are universally avoided, even when they carry secondary positive meanings in other contexts
- Ancestral name conflicts: Characters matching those used by parents, grandparents, or great-grandparents violate the 避讳 (bihui) principle and signal disrespect for family hierarchy
- Inauspicious number associations: Characters whose stroke counts or phonetic values align with unlucky numbers (particularly four, which sounds like "death") may be avoided by families who consult numerological traditions
- Overly grandiose or imperial characters: Characters like 帝 (emperor) or 圣 (sage/saint) can be seen as presumptuous, inviting bad fortune by claiming too much for a child
- Regional negative connotations: Some characters carry negative slang meanings in specific dialects or regions that don't appear in standard Mandarin dictionaries
- Characters too rare to read or type: While not a moral taboo, characters that most people cannot recognize or input on a computer create daily inconvenience and are increasingly avoided by modern parents
For writers building worlds with a chinese warrior name generator or developers creating NPCs for historical settings, these taboos matter doubly. A warrior character in a Tang Dynasty setting whose name contains characters from the reigning emperor's name would be historically impossible. That kind of error breaks immersion for knowledgeable players and readers far more than a misspelled English word ever could.
The cultural dimension also intersects with the concept of 八字 (bazi), the "Eight Characters" system based on birth date and time. Many families consult this system to choose characters with favorable stroke counts that balance the child's elemental destiny. While you don't need to replicate full bazi analysis for fictional names, understanding that naming in Chinese culture has never been casual helps explain why AI outputs feel hollow to native speakers. The names lack intentionality. They carry no sense of a parent's hope, a family's history, or a culture's accumulated wisdom about what words should and shouldn't be attached to a human life.
Cultural validation requires the deepest knowledge of any step in this process. But there's one more technical layer that trips up AI models with surprising frequency: the mapping between characters and their romanized pronunciations, where errors hide in plain sight for anyone reading names in pinyin.
Step 6: Validate Pinyin-to-Character Mapping Accuracy
An AI gives you a Chinese name in both characters and pinyin. The characters pass your structural checks, the gender signals align, and the tonal pattern flows nicely. But look closer at the romanization: does the pinyin actually match the characters? This mismatch is one of the sneakiest errors AI tools produce, because both outputs look individually correct while being completely disconnected from each other.
The problem stems from how AI models handle the many-to-many relationship between Chinese characters and their pronunciations. A single character can have multiple readings depending on context, and a single pinyin syllable can map to dozens of different characters. When a model generates characters and pinyin in parallel rather than deriving one from the other, the results often drift apart. Anyone using a chinese name translator tool or attempting to translate names from english to chinese needs to verify this mapping explicitly rather than trusting that both outputs refer to the same name.
Verifying Pinyin-to-Character Accuracy in AI Outputs
The core check is straightforward: look up each character in a standard dictionary and confirm its pronunciation matches the pinyin the AI provided. Sounds simple, but several complications make this trickier than it appears.
First, many Chinese characters are polyphonic, meaning they carry different pronunciations in different contexts. The character 乐 reads as "le" (happy) in some names and "yue" (music) in others. The character 单 functions as the surname "Shan" but means "single" when read as "dan." If an AI generates the surname 单 but romanizes it as "Dan" instead of "Shan," the name translate in chinese terms is technically wrong, even though both readings exist for that character.
Second, romanization systems themselves introduce confusion. The Library of Congress Pinyin Conversion Project documents the key differences between Hanyu Pinyin and Wade-Giles, the two most common romanization systems for Mandarin. Wade-Giles uses apostrophes to indicate aspiration (ts'ui, ch'ien) and hyphens between syllables of given names (Wang T'ieh-jen), while Pinyin joins syllables together without hyphens (Wang Tieren) and never uses apostrophes for aspiration. An AI might mix conventions from both systems in a single output, producing something like "Ch'en Mingxiao," which blends Wade-Giles surname formatting with Pinyin given name formatting.
Here are the telltale signs of each system, drawn from the Library of Congress reference:
- Pinyin indicators: Syllables beginning with B, D, G, Q, X, or Z; syllables ending in ONG, UE, or IE; joined multi-syllable given names without hyphens
- Wade-Giles indicators: Syllables beginning with HS or TS; syllables ending in UNG, UEH, or IEH; apostrophes marking aspiration; hyphens between given name syllables
If you spot a name translator in chinese output mixing these conventions, the romanization is unreliable regardless of whether the characters themselves are valid. A name should follow one system consistently.
Validating Romanized Name Outputs for International Use
When AI-generated names will appear on international documents, in databases, or in cross-border compliance systems, the romanized form needs to follow standard Pinyin conventions precisely. Compliance experts working in name screening have documented how inconsistent romanization across systems creates false negatives in watchlist matching. A name romanized as "Hsiao" in Wade-Giles and "Xiao" in Pinyin refers to the same person, but automated screening systems may treat them as different individuals entirely.
For international use, Hanyu Pinyin is the standard. Validating that an AI output follows correct Pinyin requires checking syllable boundary rules. The principle is clean: Pinyin syllables begin with a consonant or consonant cluster (ch, sh, zh), and syllable boundaries follow predictable patterns. When a single consonant appears in the middle of a joined word, it marks the beginning of the next syllable. When two or three consonants cluster together, the last one starts the new syllable.
Use this sequential process to verify pinyin-character alignment for any AI-generated chinese to english name output or its reverse:
- Isolate each character in the generated name and look up its standard Pinyin reading in a dictionary like MDBG or Pleco. Note any polyphonic characters that have multiple valid readings.
- Compare the dictionary reading against the AI-provided romanization character by character. Confirm tone marks match (first, second, third, or fourth tone for each syllable).
- Check syllable boundaries in the joined given name. For a two-character given name like "Mingxiao," verify that the break falls correctly between "Ming" and "xiao" rather than at an impossible split like "Min" and "gxiao."
- Verify apostrophe usage. Pinyin requires an apostrophe before any syllable beginning with a, e, or o when it follows another syllable within the same word. A name like "Xi'an" needs the apostrophe; without it, "Xian" becomes a single syllable with a different meaning.
- Confirm capitalization conventions. The surname should be capitalized. The given name should begin with a capital letter with remaining syllables in lowercase and joined without spaces or hyphens. "Wang Xiaoming" is correct; "Wang Xiao Ming" or "Wang Xiao-ming" signals non-standard formatting.
- Validate against a known syllable table. Mandarin has approximately 410 possible syllables. If the AI produces a syllable combination that doesn't exist in the standard Pinyin syllable inventory, the romanization is fabricated regardless of what characters accompany it.
The challenge multiplies when you need to translate names from english to chinese and back again. English phonemes don't map cleanly onto Mandarin syllables, so transliterated names often involve approximations. An AI asked to produce a Chinese version of "Christopher" might generate characters that sound vaguely similar but whose Pinyin doesn't reconstruct back to anything resembling the original English. Verifying round-trip consistency, characters to Pinyin and back, catches these drift errors.
Pinyin validation closes the loop on technical accuracy. But all six steps so far, surname verification, character validity, gender alignment, tonal harmony, cultural taboos, and romanization mapping, work best when combined into a single structured workflow, one that tells you exactly which checks to run first and when to escalate to human judgment.
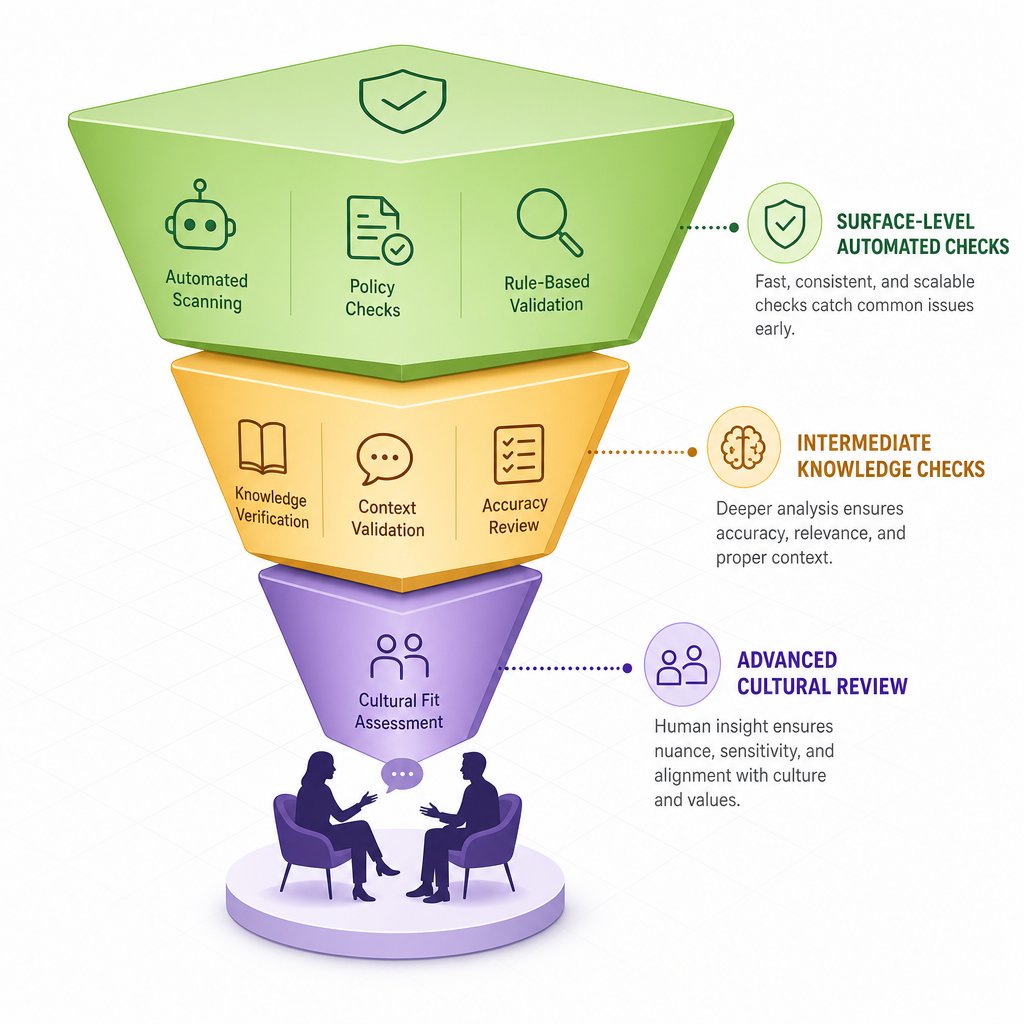
Step 7: Apply a Structured Validation Checklist With Native Speaker Review
Six distinct validation layers, each catching a different category of error. Running them ad hoc works for a single name, but when you're auditing dozens or hundreds of AI outputs, you need a structured workflow that tells you what to check first, what requires specialized knowledge, and where to draw the line between automated screening and human judgment.
The framework below organizes every check from the previous steps into three tiers based on the expertise required. Tier 1 catches the most obvious fabrications without any Chinese language knowledge. Tier 2 requires basic familiarity with characters and pinyin. Tier 3 demands cultural fluency that only a native speaker or deep specialist can provide. Whether you're running a name converter chinese tool through its paces or spot-checking a batch of AI outputs for a game localization project, this tiered approach ensures nothing slips through.
The Complete AI Chinese Name Validation Checklist
Think of this as a funnel. Names that fail Tier 1 checks get rejected immediately, saving you from wasting time on deeper analysis. Names that pass Tier 1 move to Tier 2, where character-level issues surface. Only names that survive both automated layers advance to Tier 3, where cultural nuance and native speaker intuition take over.
| Tier | Check Type | What to Verify | Tools / Resources Needed |
|---|---|---|---|
| 1 - Surface | Surname existence | Surname appears in top 400 Chinese surname lists or recognized compound surname registry | Hundred Family Surnames database, census frequency lists |
| 1 - Surface | Unicode range | All characters fall within CJK Unified Ideographs (U+4E00 to U+9FFF) | Python ord() function, Unicode lookup tools |
| 1 - Surface | Structure format | Name is 2-4 characters total (1-2 surname + 1-2 given name) | Character count check |
| 2 - Intermediate | Gender alignment | Given name characters match intended gender based on usage ratios above 0.8 threshold | Chinese Gender dataset (Harvard Dataverse), name frequency corpora |
| 2 - Intermediate | Tonal harmony | Characters don't all share the same tone; no problematic third-tone clusters | Pinyin dictionary (MDBG, Pleco), tone lookup tools |
| 2 - Intermediate | Pinyin-character match | Romanized form accurately reflects character pronunciations in one consistent system | Standard Pinyin syllable table, Library of Congress conversion reference |
| 3 - Advanced | Homophone screening | Combined syllables don't produce embarrassing or inauspicious meanings across tone variations | Native speaker review, comprehensive dictionary |
| 3 - Advanced | Cultural taboo check | No death/illness associations, ancestral conflicts, or regionally offensive connotations | Native speaker consultation, cultural naming guides |
| 3 - Advanced | Natural impression | Name sounds like it belongs to a real person of the intended age, region, and background | Native speaker judgment |
For developers building a chinese name converter pipeline or anyone using a name to chinese name converter at scale, Tiers 1 and 2 can be fully automated. A script running surname lookups, Unicode range checks, gender ratio comparisons, and tone pattern analysis catches roughly 70-80% of AI generation errors without any human involvement. The remaining errors, the cultural ones, require a different kind of intelligence entirely.
When and How to Consult Native Speakers
Programmatic checks handle structure. Reference databases handle frequency. But the question "does this name feel real?" lives in a space that no algorithm can reach. Cultural authenticity is experiential. It comes from growing up hearing names called across schoolyards, reading them on business cards, and knowing instinctively which names belong to grandmothers versus teenagers.
If you've ever wondered "what's my chinese name" or "what would my chinese name be" and asked a Chinese friend, you've already experienced this process informally. The friend doesn't consult a database. They consider your personality, the sound of your original name, cultural associations, and aesthetic balance, all simultaneously. That holistic judgment is exactly what Tier 3 validation requires.
When you bring AI-generated names to a native speaker for review, ask specific questions rather than simply asking "is this okay?" Targeted questions produce more useful feedback:
- Does this name sound natural? Would you be surprised to meet someone with this name, or does it feel ordinary?
- What impression does it give? Does it suggest a specific age range, social class, or regional background?
- Would you expect this name on a person of this age and background? A name that sounds perfect for a 1960s-born professor might feel bizarre on a 2020s teenager.
- Do you hear any unfortunate homophones? When you say it quickly in conversation, does anything awkward emerge?
- Does anything about it feel "off" in a way you can't quite articulate? Native speaker intuition often catches issues that defy easy categorization.
Native speaker consultation is the gold standard for final validation. No chinese name convert tool, automated checker, or reference database can replicate the cultural intuition of someone who has lived inside the language their entire life.
For compliance teams generating synthetic data, a single native speaker reviewing a batch of 100 names can flag cultural issues in under an hour, a trivial cost compared to the downstream problems caused by unrealistic test data skewing screening system calibration. For fiction writers, one conversation with a native speaker about your character names can prevent the kind of error that pulls Chinese-speaking readers out of your story permanently.
The validation methodology laid out across these seven steps moves from objective and automatable to subjective and human-dependent. That progression is intentional. Start with the checks that cost nothing and catch the most obvious errors. Escalate to intermediate checks that require modest expertise. Reserve human judgment for the final layer where cultural nuance lives. This approach respects both your time and the complexity of Chinese naming, ensuring that every name converter chinese tool or AI output you rely on produces results worthy of the culture they claim to represent.
Frequently Asked Questions About Validating AI-Generated Chinese Names
1. Why do AI models generate incorrect Chinese names?
AI models treat Chinese name generation as statistical pattern matching without understanding the linguistic, tonal, and cultural rules that govern real names. They absorb character frequency data from general text corpora but lack awareness of naming-specific constraints like gender associations, tonal harmony, homophone conflicts, and cultural taboos. Models trained predominantly on English data perform significantly worse on tasks requiring deep Chinese cultural knowledge, leading to outputs that contain valid characters arranged in ways no native speaker would combine.
2. How can I check if an AI-generated Chinese surname is real?
Cross-reference the generated surname against authoritative databases like the Hundred Family Surnames and modern census frequency rankings from China's Ministry of Public Security. The top 100 surnames cover approximately 85% of the population, so most valid names will use a common surname. Watch for red flags like grammatical particles used as surnames, extremely rare characters associated with negative meanings, or incorrectly split compound surnames like Ouyang or Sima that AI models often mangle.
3. What Unicode range should Chinese name characters fall within?
Valid modern Chinese name characters should primarily fall within the CJK Unified Ideographs block spanning U+4E00 to U+9FFF. Characters from CJK Extension A (U+3400 to U+4DBF) occasionally appear in regional or ethnic minority names but warrant manual review. Characters from Extensions B through I or CJK Compatibility Ideographs almost never appear in modern personal names and should be treated as strong indicators of AI hallucination when found in generated outputs.
4. How do I detect gender mismatches in AI-generated Chinese names?
Chinese given name characters carry strong gender associations rooted in their semantic fields. Feminine characters typically relate to beauty, flowers, jade, and grace, while masculine characters reference strength, ambition, and natural grandeur. Research shows over 80% of Chinese people carry names with a gender ratio above 0.9. To validate, cross-reference each given name character against gender-usage datasets like the Chinese Gender dataset on Harvard Dataverse, flagging any name where strongly gendered characters contradict the intended gender.
5. When should I consult a native Chinese speaker for name validation?
Native speaker review becomes essential after automated checks pass, specifically for detecting homophone conflicts that create embarrassing meanings, identifying cultural taboos around death or ancestral naming conventions, and assessing whether a name sounds natural for a person of a specific age, region, and social background. Ask targeted questions about the name's impression, any awkward homophones heard in casual speech, and whether anything feels intuitively wrong. This human layer catches cultural nuances that no algorithm can replicate.


